Давно я уже не писал про новые фичи SQL Server, но до релиза остаётся всё меньше и меньше времени, а много возможностей Denali ещё не описаны :) Сегодня я расскажу о новой фиче, которую назвали FILETABLE.
FileTable основывается на функционале FILESTREAM, появившемся в 2008-й версии. Давайте быстро вспомним что он из себя представляет. FILESTREAM позволяет хранить файлы в базе данных, при этом сохраняя возможность потоковой работы с файлами. Таким образом мы поддерживаем ссылочную целостность базы данных и файловой системы. Более подробно можно прочитать здесь - Введение в FILESTREAM. На презентациях и в теории всё выглядит очень красиво, но на самом деле, если попробовать использовать FILESTREAM сталкиваешься со множеством ограничений, да и сам код работы с подобными файлами красотой не блещет (открываем транзакцию в БД, получаем дескриптор файла и т.д.). Одним из ограничений FILESTREAM была синхронизация БД и файловой системы. Удаление записи в базе приводило к удалению файла (тут всё ок), а вот удаление файла не приводило к удалению записи и приводило к ошибке при обращении к этой записи. Кроме этого недостатка, файлы на файловой системе получали совершенно нечитаемые имена и находились в папке, указанной при создании базы данных. На самом деле FileTable не устраняет эти недостатки FILESTREAM, но успешно позволяет абстрагироваться от них. Суммируя всё вышесказанное, FileTable это не замена, а скорее надстройка над FILESTREAM. Впрочем вы это и сами увидите по ходу изложения.
Как я уже говорил, FileTable поддерживает полную синхронизацию файловой системы и базы данных и, по сути, является полным отображением структуры папки в виде таблицы. Но мы не можем просто взять любую папку с файлами на жёстком диске и сказать сиквел серверу: “А сделай-ка мне на основе этой папки FileTable”. Нам, как и для работы с данными FILESTREAM, нужно включить FILESTREAM на уровне сервера и создать БД с FILESTREAM файловой группой (здесь и будут храниться данные FileTable). Ну а дальше, уже на основе всего этого будет создана FileTable с полной синхронизацией БД и файловой системы. Не буду вдаваться в подробности, давайте лучше посмотрим на примере как это всё настроить, как это работает, какие преимущества нам это даёт и какие недостатки есть у FileTable.
В первую очередь нам нужно включить FILESTREAM на уровне сервера (через свойства инстанса в Configuration Manager) для доступа к содержимому файла и с помощью T-SQL и из файловой системы:

Затем разрешить доступ при помощи процедуры sp_configure (двойка означает T-SQL доступ + потоковый доступ):
sp_configure 'filestream access level', 2
RECONFIGURE
Теперь всё готово к созданию БД в которой мы будем создавать FileTable. Вот скрипт на создание базы данных:
CREATE DATABASE FileTableDemo ON PRIMARY (NAME = N'FileTableDemo', FILENAME = N'D:\SQL_DATA\FileTableDemo.mdf'),
FILEGROUP FilestreamFG CONTAINS FILESTREAM (NAME = FilestreamFG, FILENAME = 'D:\DatabaseFiles')
LOG ON ( NAME = N'Denali_FileTable_log', FILENAME = N'D:\SQL_DATA\FileTableDemo.ldf')
WITH FILESTREAM ( NON_TRANSACTED_ACCESS = FULL, DIRECTORY_NAME = N'FileTableDemo')
GO
Здесь, обратите внимание на то, что в базе данных должна присутствовать файловая группа, которая будет содержать FILESTREAM (файлы) данные. И здесь (внимание!) никаких чудес нет! Файлы будут храниться на жёстком диске именно в этой папке и этой файловой группе, которую вы указали при создании БД. Файлы всё так-же будут иметь кривые имена, и, после удалении файла из этой папки и обращении потом к соответствующей записи в FileTable даст вам вот такую ошибку: A transport-level error has occurred when receiving results from the server. FileTable – это надстройка над FILESTREAM, и использует ту-же модель хранения данных. Но, несмотря на это, FileTable предлагает нам новую, более продвинутую, модель работы с файлами, и позволяет абстрагироваться от недостатков FILESTREAM.
Для того, чтобы понять что-же за преимущества нам даёт FileTeble, давайте посмотрим на параметры условия WITH FILESTREAM: DIRECTORY_NAME задаёт имя сетевой папки, которая будет создана при создании БД (будет создана сетевая папка с именем как у инстанса, а внутри неё папка, указанная в DIRECTORY_NAME); NON_TRANSACTED_ACCESS = FULL разрешает нетранзакционный доступ к файлу (если помните, то работа с FILESTREAM файлами была полностью транзакционной: мы открывали транзакцию в БД, получали контекст тарнзакции и потом работали с файлом через объект SqlFileStream). С FileTable у нас появляется прямой доступ к папке с файлами (через сетевой ресурс), где папки и файлы имеют понятные имена и мы можем с ними работать как с обычными файлами. При этом они всё равно будут находиться под контролем SQL Server и данные, хранящиеся в FileTable будут полностью синхронизированы с жёстким диском. Ну и давайте, собственно, посмотрим на сами FileTables.
Создать FileTable можно при помощи следующей инструкции:
USE FileTableDemo
GO
CREATE TABLE Books AS FILETABLE
WITH
(
FILETABLE_DIRECTORY = 'Books',
FILETABLE_COLLATE_FILENAME = database_default
)
GO
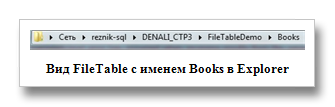
После чего можно открыть Explorer, посмотреть на созданную структуру папок и наполнить папку файлами:

Но помните, что на самом деле ваши файлы находятся здесь, и выглядят вот так (удаляя или добавляя файл сюда, изменения в FileTable не произойдут, т.к. эта папка управляется исключительно SQL Server, и вмешиваться в работу этого механизма не стоит):

Теперь давайте посмотрим, что же хранится в нашей FileTable:
SELECT name, path_locator.ToString(), file_type, cached_file_size, is_directory
FROM Books
GO
Результат будет следующим:

Количество и наименование полей в FileTable не может быть изменено. Количество полей намного больше,чем в представленном мной результате запроса. Про все я рассказывать не буду (их описание можно найти здесь – File Table Schema), но на некоторых всё-же хочу остановиться:
- stream_id – Уникальный идентификатор записи. Ввиду того, что схему таблицы нельзя менять, единственным вариантом для добавления дополнительной информации остаётся вторая таблица, и связь с FileTable по этому полю.
- file_stream – Столбец типа varbinary(max) с атрибутом FILESTREAM. По сути это и есть содержимое файла.
- name – Имя файла. Наряду с этим столбцом есть ряд других, которые отображают атрибуты файла (creation_time, is_hidden, и т.п.)
- path_locator – Место файла/папки в иерархии. Имеет тип HierarchyId.
- file_type – Расширение файла. Как и в случае с FILESTREAM кроме просто отображения расширения это поле нужно ещё и для индексации файла полнотекстовым поиском.
Обратный эксперимент по удалению записи из таблицы проводить не буду, можете попробовать это сделать сами. В скором времени собираюсь написать ещё один пост на эту тему в котором покажу разницу в работе с файлами просто через FILESTREAM и через FileTable.
Сегодня, кроме простого обзора функционала FileTable, мы немного заглянули под капот этого функционала и посмотрели механизмы на которых он основан. В целом концепция FileTable очень интересна, в особенности для корпоративного сектора. FileTable выводит управление файлами внутри базы данных на новый уровень. Я думаю она найдёт своё применение, как в уже существующих приложениях, так и в новых разработках.
Ссылки по теме: